Finding Slow Queries in Postgres Using Datadog
You’re starting to notice lags in your application's performance. Page loads are slowing, and the user experience is being impacted. At the same time, your AWS bills are also starting to creep up.
These can be the tell-tale signs of serious database performance issues. Your queries are taking too long to execute and are using too many resources when they do. The answer most people move to is to start caching queries to reduce the load on your database. This is exactly what we built Readyset for.
But which queries? Databases like Postgres have some performance monitoring capabilities, but these are clunky to use, and you’ll end up knee-deep in statistics configurations. The answer is to add application performance monitoring (APMs) into your stack. APMs, like Datadog, make it easier to monitor your database performance and can give you insights into how your database and queries perform.
Here, we’ll show how you can use Datadog and query metrics to understand your queries better and prioritize candidate queries for caching.
Use Query Metrics to Identify High-Load/High-Call Queries
The Datadog Query Metrics dashboard provides insights into the performance of normalized queries. You can visualize performance trends and filter and group queries to analyze how queries perform. The dashboard graphs key metrics like requests and average latency and gives metrics for timing, requests, and the amount of data pulled per normalized query.
Let’s go through how these can be used to find good caching candidates.
Using AVG LATENCY and ROWS/QUERY to identify load
High average latency can indicate that a query could be more efficient or that the database is struggling to execute it quickly, leading to performance bottlenecks.
If we look at this Query Metrics dashboard, we can see that there are a few queries with high average latency:
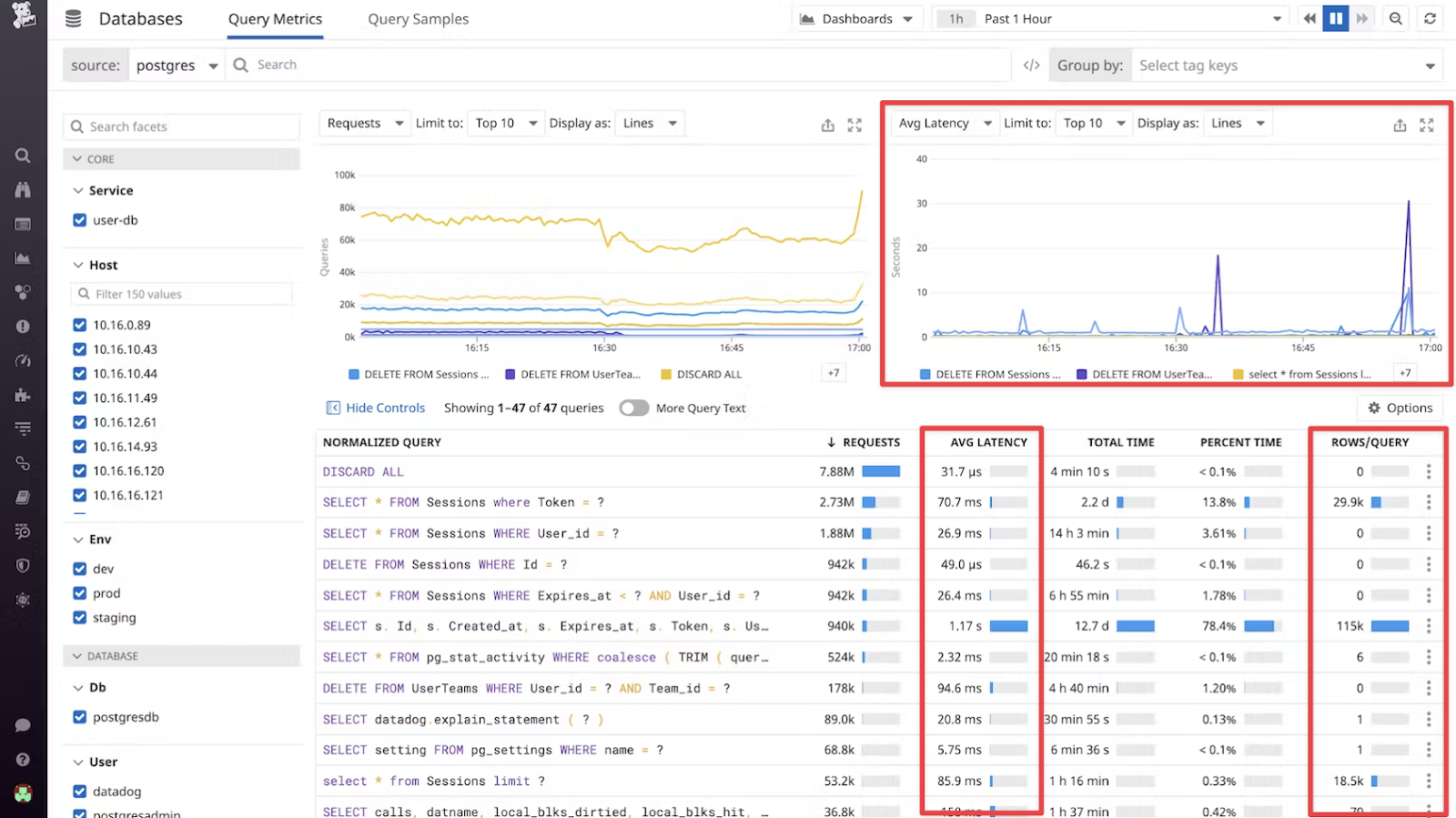
The line graph for AVG LATENCY (top right) shows the average time it takes for queries to execute over a specific period. Spikes in this graph indicate periods where queries are taking longer to execute, which can indicate high-load conditions or performance issues within the database.
The two main spikes in the short time frame of the graph (one hour) both relate to write operations:
- DELETE FROM UserTeams WHERE User_id = ? AND Team_id = ?.
- DELETE FROM Sessions WHERE Id = ?
As delete operations, these can’t be cached. However, looking at the other queries in the list, we can see some SELECT queries with long average latencies. For instance, the “SELECT s. Id s…” query seems to have a long latency, so could be a good candidate for caching.
The cumulative time spent on this particular query (“TOTAL TIME”) and the proportion of the total database time that is consumed by this query (“PERCENT TIME”) is also high–over three-quarters of database time is spent on this query. It means it is a dominant consumer of database time and is likely to significantly contribute to performance issues.
A further pointer in this direction is the average number of rows processed per query execution (“ROWS/QUERY”). A high number of rows per query can suggest that the query is processing a large amount of data, which might be optimized for better performance.
This should be a query investigated for caching. And if it can’t be cached, it should be optimized to reduce the load on the database.
Using REQUESTS to analyze query frequency
Beyond the load of an individual query on the database, caching candidates can also come from analyzing query frequency.
The frequency of queries is a critical aspect of database performance. High-frequency queries, especially if they are resource-intensive, can contribute significantly to the load on the database. If specific queries are executed often, they can become candidates for optimization, such as by improving the query's efficiency, adding indexes to speed up execution, or caching the results when possible to reduce the load on the database.
In Datadog, we can look at REQUESTS to understand frequency:
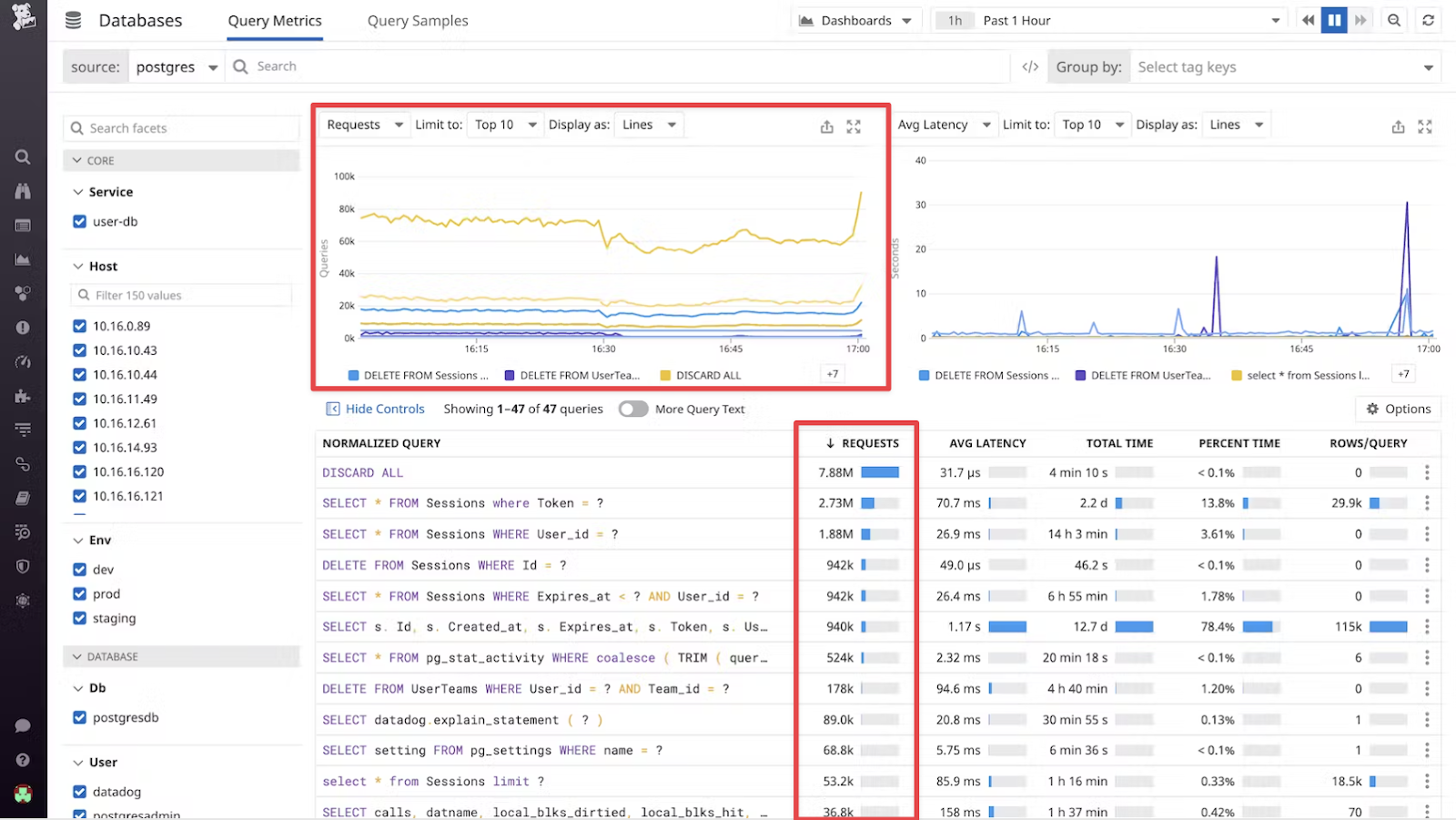
The REQUESTS graph (top left) displays the number of queries over time, segmented by normalized query. There are fluctuations in query frequency, which can indicate peak usage times or potential bursts of activity that could stress the database. The table below provides more detailed data on the frequency of specific queries, with the "REQUESTS" column showing the total number of executions for each query.
This data helps identify which queries are run most frequently and may contribute to performance issues, particularly during peak activity periods, as shown in the graph. The two top SELECT queries have millions of requests between them. This means that they could be good options for caching, as optimizing them could lead to significant performance improvements.
Frequent execution implies that even minor efficiencies gained per query can substantially reduce the overall database load. Caching can serve repeated requests without needing to access the database each time, thus freeing up resources for other operations and improving the application's responsiveness.
Use Explain Plans to Evaluate Query Cost
Explain plans are a great feature of database statistics that provide insight into how the SQL optimizer will execute a query. They show the query execution path chosen by the database, including which indexes will be used, how tables are joined, and the estimated cost associated with each operation. By understanding explain plans, developers can identify potential performance issues and optimize queries, leading to faster execution and more efficient resource use.
You can generate an Explain plan within SQL using the EXPLAIN command:
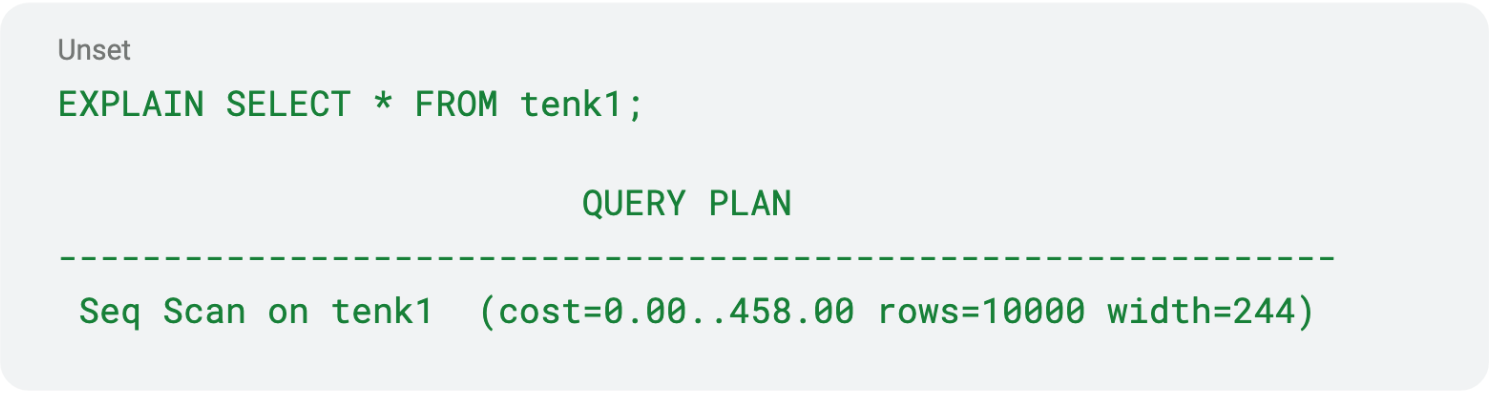
Here, the startup cost of this query is 0, but the total cost is 458. That 458 is unitless but is a representation of the resources required to scan the table or index. It has to scan 10,000 rows, and each row is 244 bytes. By using EXPLAIN with different queries, you can understand how the SQL optimizer is traversing data and what optimizations can be made.
Datadog provides an excellent visual representation of an explain plan:
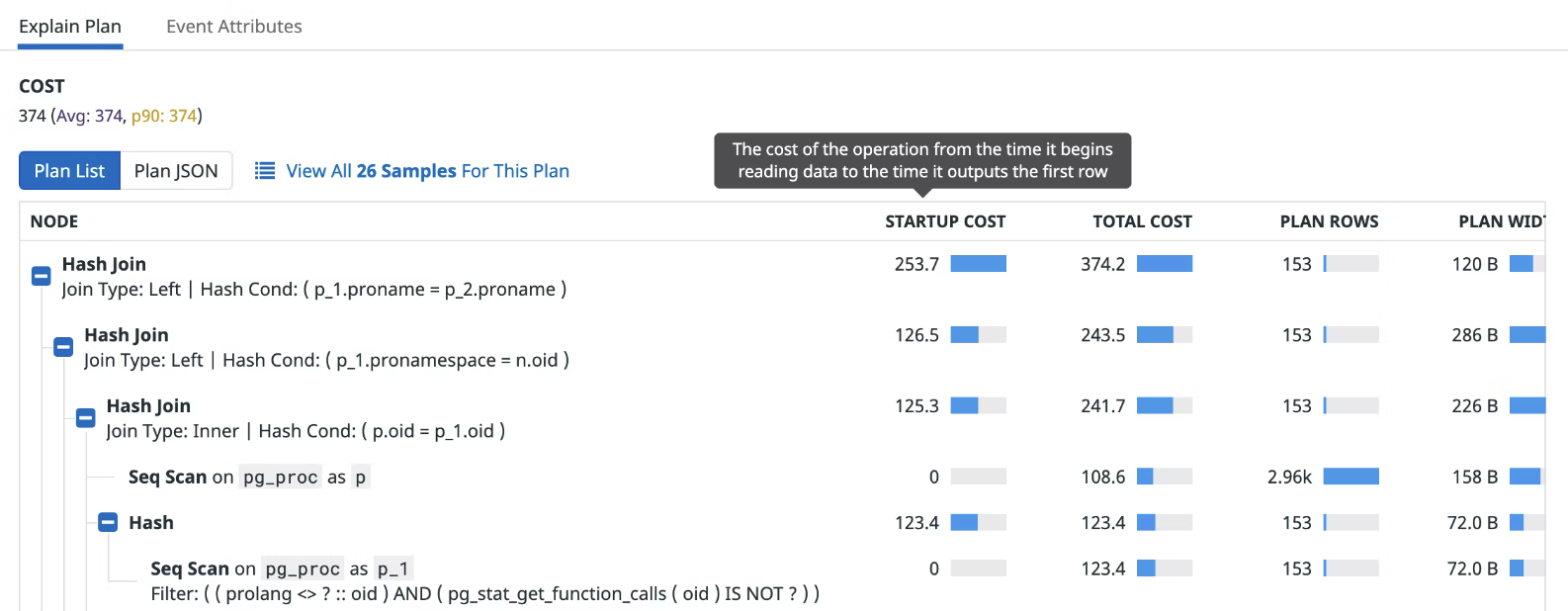
For more complex queries, it visualizes the most efficient way to execute a given query by considering various query plans. This is a good proxy for latency and overall resource consumption of specific queries.
In this specific plan, several "Hash Join" operations are shown, which are common in executing queries involving joining tables. The sequential scan ("Seq Scan") on pg_proc indicates a full scan of that table, which could be costly if the table is large.
The importance of this data lies in the ability to analyze and optimize queries. Operations with high costs could be targets for optimization. For example, if a sequential scan has a high total cost, it might be beneficial to consider indexing the scanned table to reduce the cost. The plan rows and plan width can also inform decisions about indexes and query structure.
Caching can also benefit high-cost queries as it reduces the need to perform expensive operations multiple times.
Monitor Throughput and Latency During Peak Times to Identify Bottlenecks
A database isn’t under constant load. Instead, load ebbs and flows over days, weeks, and months, depending on the type of service your application provides. Thus, you must identify peak load times to understand when caching data is most helpful.
You can use Datadog’s real-time monitoring to observe query performance during high-traffic periods, use historical data to predict future peak periods, and prepare by caching the most impactful queries.
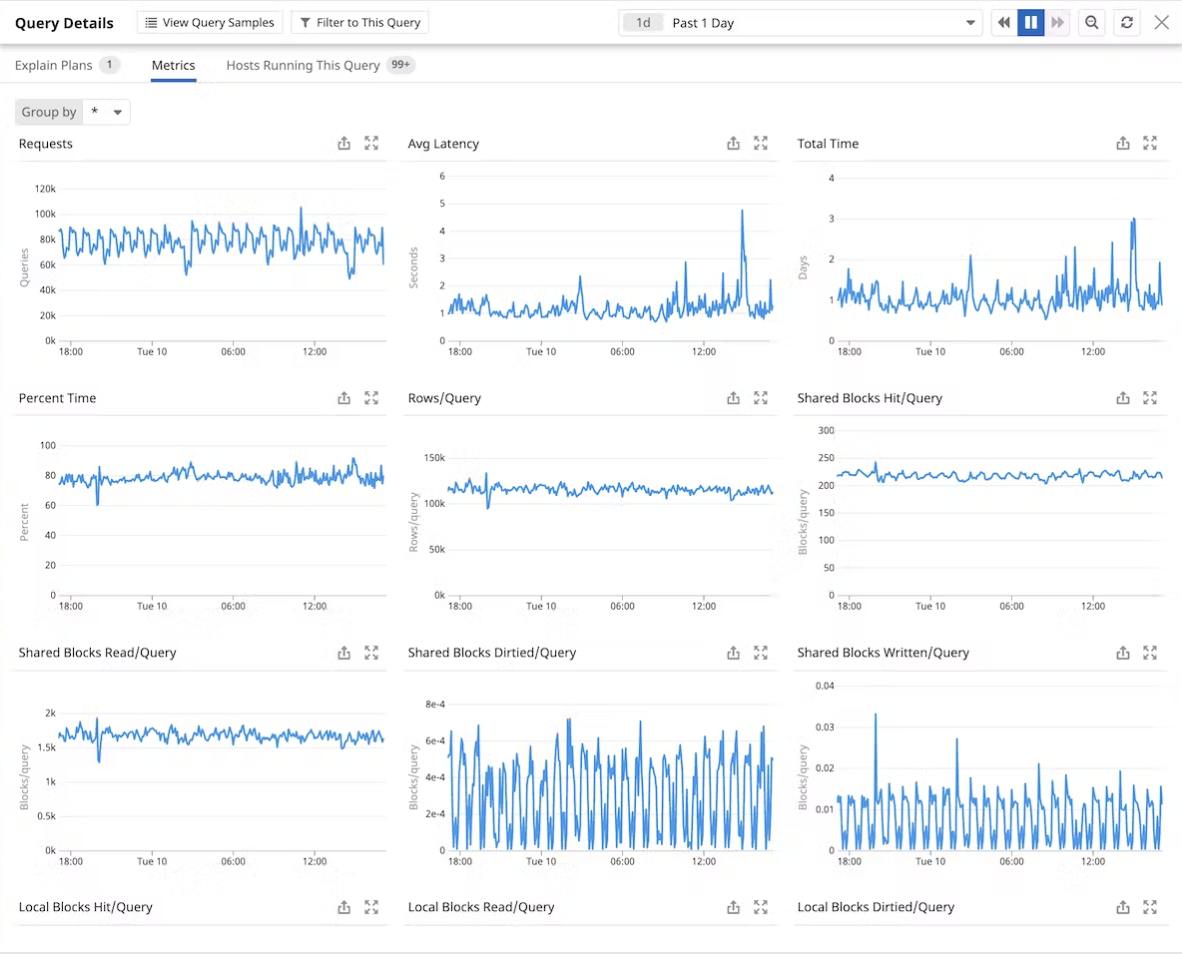
By looking into the Query Details of a given query (that you have identified through explain plans and analysis of the metrics above), you can see when this particular query is putting strain on the system. Here, you can look at:
- Requests. Peaks in this graph can indicate high traffic periods.
- Avg latency. Spikes may suggest that queries take longer, possibly due to high load or inefficient execution plans.
- Total time. Spikes can indicate periods where the query is consuming more resources.
- Percent time. High consistent values or peaks suggest the query is a significant part of the database workload.
- Rows/Query. Consistently high numbers indicate heavy data retrieval, which can impact performance.
This is a query-specific breakdown of the metrics from the main dashboard. Monitoring these metrics helps identify peak times for query load and execution times, critical for capacity planning, identifying potential bottlenecks, and optimizing database performance.
By analyzing these graphs, developers can identify when and what to cache to reduce loads at peak times.
Integrating Datadog With Postgres
Leveraging APMs like Datadog is critical to enhancing database performance and user experience.
If this has whetted your appetite for adding more monitoring to your database so you can understand query metrics, optimize performance, and cache complex, intensive queries, then you can add Datadog to any Postgres (or other) database.
Datadog has written a series on Postgres performance and how to integrate Datadog into your application and expand on some of the techniques here.
Start Caching Slow Queries with Readyset
By identifying high-load queries, analyzing their frequency, evaluating their cost, and monitoring performance during peak times, you can set the stage to strategically cache the right queries which leads to faster page loads, a smoother user experience, and reduced costs.
Readyset Cloud makes the caching process easy. Sign up to start caching queries in fifteen minutes or less without making any changes to your application code.