Don’t use key-value stores to cache from relational databases
Your app is starting to see traction, and your database is feeling it. Query latencies are creeping up, and you can see it starting to falter under the load. You know you’re only one good story on HN away from an outage.
This is an exciting problem to have, but it is a problem, and it’s come at the worst possible time. Typically, it’s one you turn to caching for: adding caching to your application's queries greatly reduces the burden on your primary database for your frequently issued and heavy-hitting queries. Caching is the most direct path to serving web requests in a fraction of the usual time.
So, you decide it’s time to reach for an in-memory key-value store like Redis or Memcached. Doing so is the standard approach for in-memory caching, but it comes along with both immediate and long-term problems for an engineering team.
There’s a better way to do this. Before we dive in, it’s important that we first grok what exactly makes this standard approach so complex. Let’s get to it.
Problem #1: Mismatched data models
When you first set out to build your app, you had to decide on which data store should be your source of truth, and how you’d access it. In all likelihood, you chose vanilla: a relational database like Postgres and the default ORM that ships with your web framework.
As a result, your entire application is written in a way that makes a strong assumption about the shape of your data and how you can interact with it, and for better or for worse, most of the nitty-gritty details about how high level constructs in your code map onto your database have been abstracted away from you.
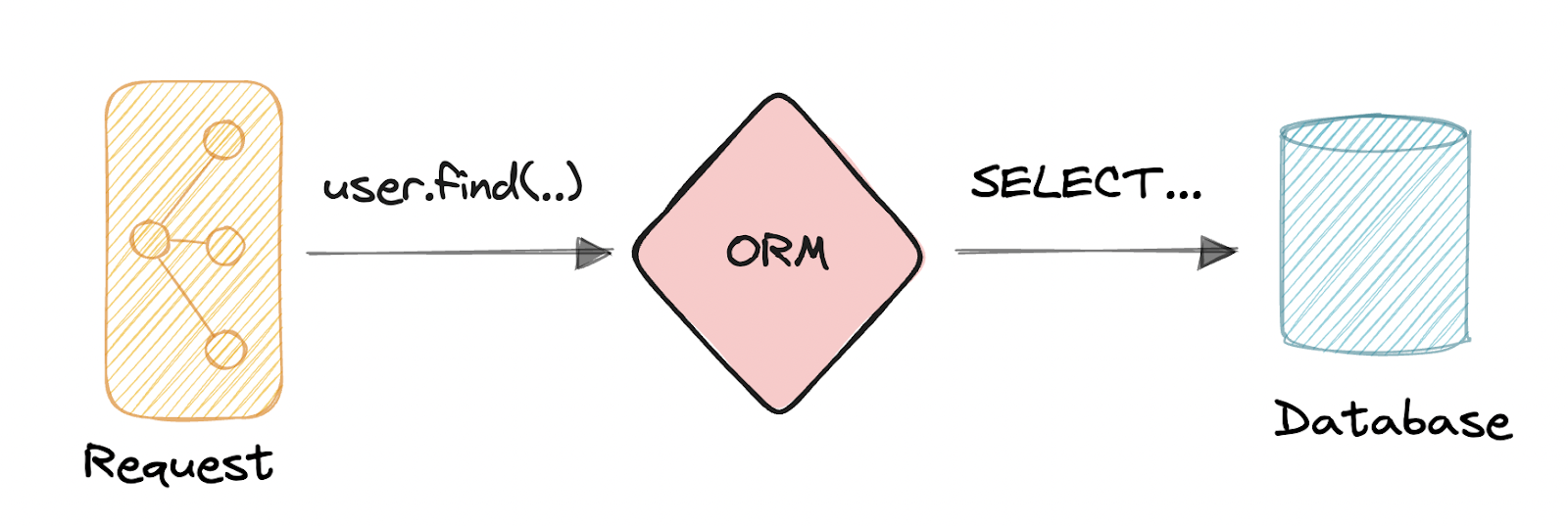
Now that you’re starting to see scaling challenges, you’re planning to add a third party into the mix: the in-memory key-value store.
Unfortunately, your database and this key-value store have fundamentally different views on the world. A database consists of a set of tables under a relational data model, addressable via a highly expressive query language. A key-value store is just that: a single table mapping keys to values.
This means that to cache the result of a query, you have to manually translate between these two differing world views. Using an ORM to talk to your cache isn’t an option, so now you have to add new logic in all parts of the code where you want to cache that specifies how and when you should populate the cache with frequently accessed query results.
You’re adding a substantial amount of hard-to-read auxiliary code to your previously squeaky clean business logic. This increases tech debt in your application, but it isn’t the hard part, comparatively. That brings us to problem two.
Problem #2: Manual synchronization of two independent data stores
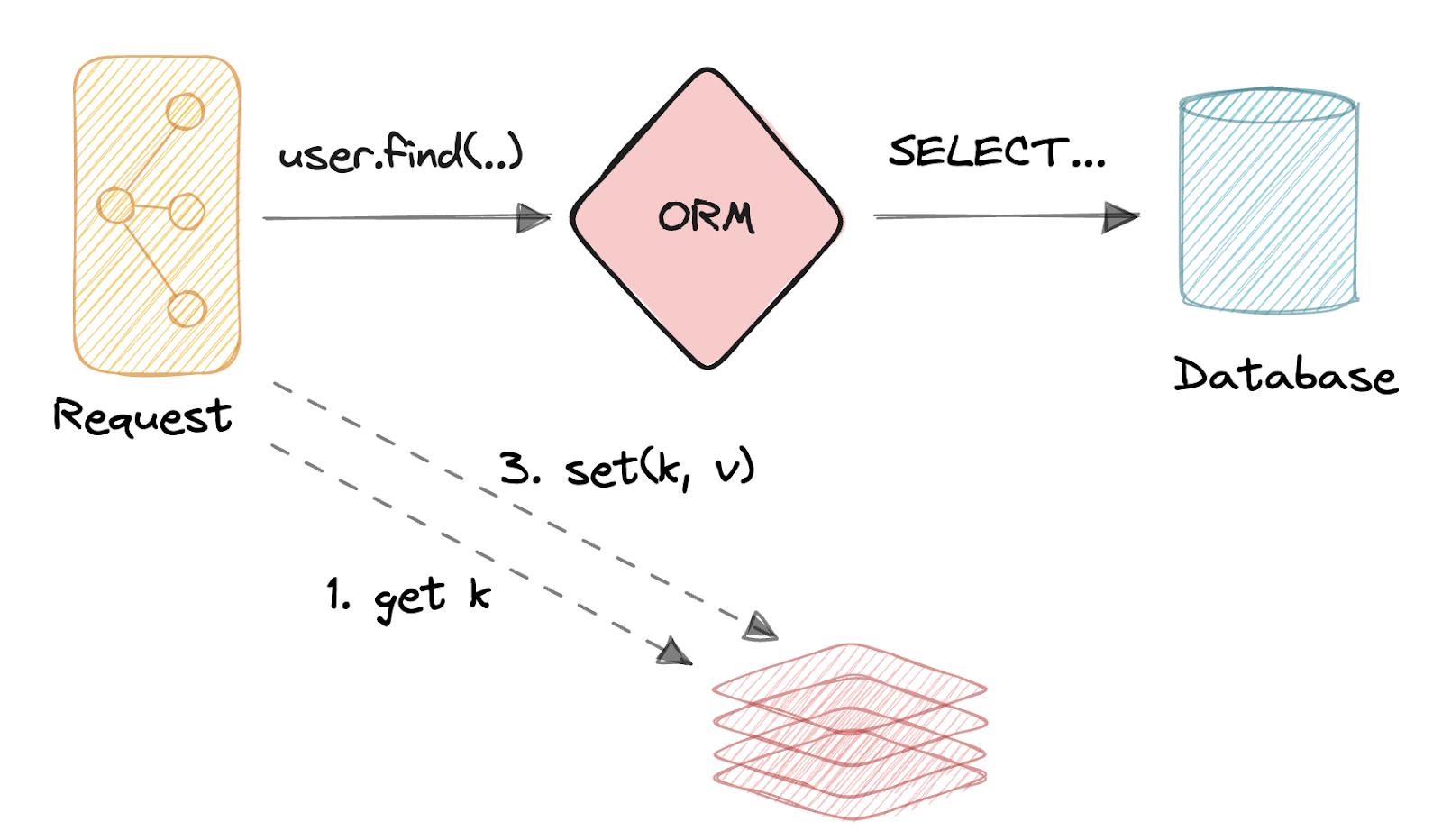
You’ve filled your cache with frequently accessed query results, but now you have to account for how these results will change as the data in your database changes.
As users interact with your web app, their web requests issue INSERT/UPDATEs that will make your source of truth database and cache quickly go out of sync. In the background, your app will be reading stale data from the cache and returning wonky results to the end users.
To rectify this situation, you’ll have to go face to face with what is considered to be the hardest problem in all of computer science: cache invalidation.

A straightforward approach to try is to just set a TTL (time to live) on the cached results. If a result has been sitting in a cache for longer than the TTL, then the next time the cache is accessed it will update the result directly from the database.
Let’s say you set it to update every minute, to try to limit how stale the results that you are returning are. This sounds reasonable, but the fundamental problem still holds true (waiting one minute to see fresh results is still a long time for an end user) and moreover now you’re sending more queries to the database, which means you have a worse cache hit rate and query performance.
This is the fundamental tension: you want to evict cache entries often enough to ensure bounded staleness on returned results, but you also want to avoid repeatedly rerunning queries all of the time since that is antithetical to the point of having a cache to begin with.
To try to avoid these tensions, you could always consider a more sophisticated cache invalidation strategy. For instance, you could add additional logic in parts of your app code that modify data in your database to also manually delete and recompute entries in your cache. For example, if a row is added to a table, you could add logic to invalidate any cache entries that could be impacted by that change.
One problem: the queries you’re caching are likely to involve complex computations over the raw inputs. Think joins, filters, aggregates, the works. In your key-value store, your information is limited to (perhaps) the query string which serves as the key (assuming you didn’t swap it out with an ID or another more compact representation) as well as the result of that query, the value. Moreover, since you’re using an ORM, in most cases the specific query that is being run is obfuscated away from you.
Tracking data provenance is no walk in the park under these circumstances. Figuring out exactly which cache entries should be updated whenever a row in a table in your database gets updated is a non-trivial and error prone task for a single query, let alone for all of the ones you’re interested in caching.
Query caching is a nightmare dressed as a daydream
If you can get cache invalidation working just right, caching can be a huge unlock when it comes to boosting the performance of your application. After all, O(1) reads independent of query complexity can be pretty nice.
However, in practice, the implementation details are a nightmare to get right: cache invalidation challenges and the ensuing distributed systems bugs are enough to make even the most experienced engineer run for the hills.
Enter Readyset: the modern approach to query caching
Query caching often ends up feeling like a last resort, but it doesn’t have to be. At Readyset, we’re building a new kind of query cache that you can plug into your database and application without making code changes or worrying about cache invalidation. Readyset has the same data model as your relational database, automatically synchronizes cache entries with your database, and is just as fast as Redis/Memcached. Let’s see how:
Readyset is relational and wire-compatible.
Readyset is SQL-native. Its data model is relational, just like your database’s, so no translation between the two is necessary. Moreover, it’s wire-compatible with Postgres and MySQL, so you can connect to it as you would a normal database or read replica by using your off-the-shelf ORM or database driver.
When you first connect to Readyset, it will proxy all of the traffic it gets to your primary database. Then, rather than specifying what to cache in your code, you tell Readyset which of these proxied queries to cache by running a SQL-like command against it. That’s it.
Readyset automatically updates cache entries without eviction.
Rather than evicting cache entries and rerunning the queries against the database to ensure that data is kept fresh, Readyset uses your database’s replication stream to update cached query results.
Readyset never issues queries against your database to accomplish this. It has its own query engine that uses incremental view maintenance to update the out-of-date query result to incorporate the new data it sees. It does this behind the scenes while serving the old result so you don’t see a performance hit while the cache is being updated.
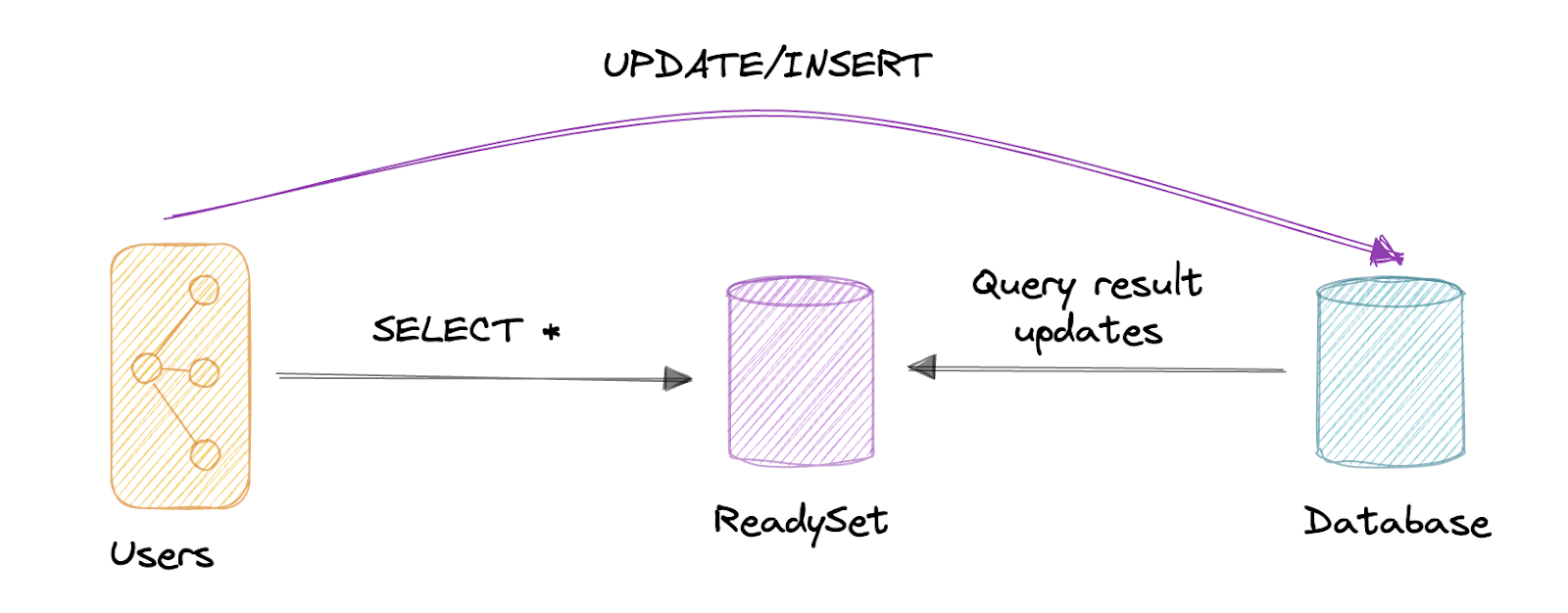
This scheme allows you to get the best performance from your query cache with minimal engineering overhead and complexity. Check out a full video demo of caching in action here.
Questions? Feedback? We’d love to hear what you think. Try out Readyset by following along with our quickstart today.