A Practical Guide to Caching: What to Cache and When
Caching is a Goldilocks problem. Caching too much leads to stale data, memory bloat, and a lot of cache management. Caching too little leads to longer latencies, higher database load, and the need to provision more and more storage.
The aim is to cache just right, optimize cache performance, minimize database load, and enhance overall system efficiency.
This is a lot easier said than done. How do you know what to cache and when? Modern databases help you understand the usage patterns of your data, including the frequency of reads versus writes, the size of the data being accessed, and the variability of query response times. These metrics are critical in informing your caching strategy, enabling you to identify hotspots of frequent access where caching can provide the most benefit. Here, we want to take you through determining what you should cache and when using the insights your database can provide.
Analyzing Workload Patterns
Understanding workload patterns in your production database is crucial for effective caching, as it directly influences what data to cache and the caching strategy to employ.
Read/Write Ratio Analysis
The read/write ratio analysis is fundamental to understanding workload patterns in database systems. This ratio illustrates the frequency of read operations (like SELECT queries) compared to write operations (INSERT, UPDATE, DELETE). A thorough analysis of this ratio can guide decisions on what data to cache and how to manage the cache effectively.
A high read ratio indicates that data is frequently accessed but only sometimes changed. This is ideal for caching because it doesn't require frequent invalidation or updates once data is cached. A high write ratio suggests more dynamic data, which can lead to frequent cache invalidations and reduced cache effectiveness.
The basic steps for analyzing your read/write ratio are:
- Data collection. Use database monitoring tools or query logs to collect data on read and write operations. Some databases provide built-in tools or extensions (e.g.,
pg_stat_statementsin PostgreSQL) that can simplify this process. - Quantify operations. Count the number of read and write operations over a given period. This can be done through script automation or database monitoring tools.
- Calculate the ratio: Compute the proportion of reads to writes. A simple formula could be: Read/Write Ratio = Number of Reads / Number of Writes.
In Postgres, we can use the pg_stat_statements extension:
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;And then query pg_stat_statements:
SELECT query, calls, rows
FROM pg_stat_statements
WHERE query LIKE 'SELECT %' OR query LIKE 'INSERT %' OR query LIKE 'UPDATE %' OR query LIKE 'DELETE %';This will show you the frequency of SELECT statements versus INSERT, UPDATE, and DELETE statements. You can then calculate the read/write ratio from these counts.
High read/write ratios (e.g., 10:1) indicate that the data is read ten times more often than it is written to. This data is a good candidate for caching. A low read/write ratio (e.g., 1:2) indicates more writes than reads. You need to be cautious about caching this data for this type of data, as the cache would need frequent updates or invalidations.
For data with a high read ratio, you can cache and set a longer Time-To-Live (TTL) for that cache. If you are caching low read/write ratio data, you must design an efficient cache invalidation strategy to ensure data consistency.
Temporal Locality and Hotspots
Temporal locality is based on the principle that recently accessed data will likely be accessed again soon. This pattern is a key factor in identifying 'hotspots' in your data - areas where frequent access suggests a high potential benefit from caching. Understanding and identifying these hotspots allows for a more targeted and efficient caching strategy, improving performance and resource utilization.
To identify hotspots, you need to:
- Monitoring access patterns. Use database monitoring tools to track access frequency to different data elements. Look for patterns where specific rows, tables, or queries are accessed repeatedly.
- Analyze query logs. Analyze logs for repeated access to specific queries. Frequent execution of the same query, especially within short time frames, indicates a hotspot.
- Understand usage metrics. Collect metrics such as the number of hits, execution time, and frequency of access for various database elements.
To understand the access frequency, you must configure your database to log detailed query information. In your postgresql.conf, you can set the following parameters:
logging_collector = on # enable logging.
log_directory = 'pg_logs' # specify the directory for log files.
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # set the log file naming convention.
log_statement = 'all' # log every executed statement.To analyze the logs, you can use something like pgBadger. pgBadger will parse the log and create an HTML report showing detailed query statistics.
Suppose you have a query log from a Postgres database and notice that specific user profiles are accessed frequently. Temporal locality suggests that user profiles accessed in the last day will likely be reaccessed.
Data or queries identified as hotspots are strong candidates for caching. The user profile data in the above example should be prioritized for caching. This is how we cache at Readyset, a process called partial materialization:
This allows us to cache relevant data while also reducing memory overhead. The goal is to minimize latency and database load by caching data showing repeated access patterns over time. By focusing on the most frequently accessed data, you can significantly improve the performance of your database and applications, ensuring that resources are allocated efficiently and that the cache serves its purpose effectively.
Query Analysis and Profiling
Query analysis and profiling are critical aspects of understanding and optimizing database performance. By using query analysis tools and techniques like the EXPLAIN command and examining query execution plans, engineers can gain insights into how queries are executed, which are resource-intensive, and how they can be optimized. This information is invaluable in making informed decisions about caching strategies.
An execution plan shows how the database engine executes a query, including steps like scans, joins, sorts, and aggregations. The EXPLAIN command in SQL provides the execution plan for a query. It reveals the database's operations and their CPU and I/O cost.
To use EXPLAIN with Your Query, just prepend your SQL query with EXPLAIN. For instance:
EXPLAIN SELECT * FROM user_logs WHERE user_id = 1234;This will output the execution plan without actually running the query. You are looking for operations like sequential scans, index scans, sorts, and joins:
Seq Scan on user_logs (cost=0.00..155.00 rows=5000 width=132)
Filter: (user_id = 1234)In this case, we have a sequential scan, indicating the query is scanning the entire user_logs table. This can be inefficient for large tables. It also shows a filter is applied to the user_id, which is inefficient if this operation is frequent or the table is large (you should use indexes instead).
The estimated cost and number of rows affected help assess the query's efficiency. Cost is a unitless measurement used by Postgres to estimate the relative expense of executing the query. It combines I/O, CPU, and other factors to help compare the efficiency of different query plans.
The lower the cost, the more efficient the query is expected to be. Queries that run frequently and have high costs are prime candidates for caching. Queries that involve significant data retrieval and minimal updates are ideal for caching.
Effective query analysis and profiling allow engineers to identify performance bottlenecks and optimize query execution. This is a crucial step in determining which data or queries will benefit most from caching. Regularly profiling queries, especially resource-intensive or frequently executed, can significantly enhance database performance and overall application efficiency.
Query Latencies
Query latencies, the time taken to execute database queries, are a crucial metric in workload analysis. They provide insight into the performance of the database and are instrumental in identifying which queries might benefit most from caching. High latencies often indicate bottlenecks or inefficiencies that can be alleviated through strategic caching. For engineers, measuring, analyzing, and interpreting query latencies are key to optimizing database performance.
We can set log_min_duration_statement in postgresql.conf to log queries that exceed a specified execution time.
set log_min_duration_statement=1000;This allows us to look for queries with consistently high execution times, as these are primary candidates for optimization and caching. You want to be able to analyze patterns in this data to determine if high latencies are isolated incidents or part of a pattern. Recurring high latencies during certain operations or times indicate systematic issues.
For example, after enabling query logging in PostgreSQL, you might find:
LOG: duration: 1050 ms statement: SELECT * FROM products WHERE category = 'Electronics';This indicates that the query took 1050 milliseconds, which might be considered high for this operation. High latencies often point to performance bottlenecks. These could be due to unoptimized queries, lack of appropriate indexing, or heavy load on the database. Queries with high read latencies and low write operations are excellent candidates for caching. For instance, caching its results could significantly improve performance if the product query above is read-heavy and the data doesn't change often.
Regularly monitoring and analyzing query latencies ensure the caching strategy aligns with current usage patterns and performance requirements.
Readyset shows you the latencies for each of the queries you are running through it:
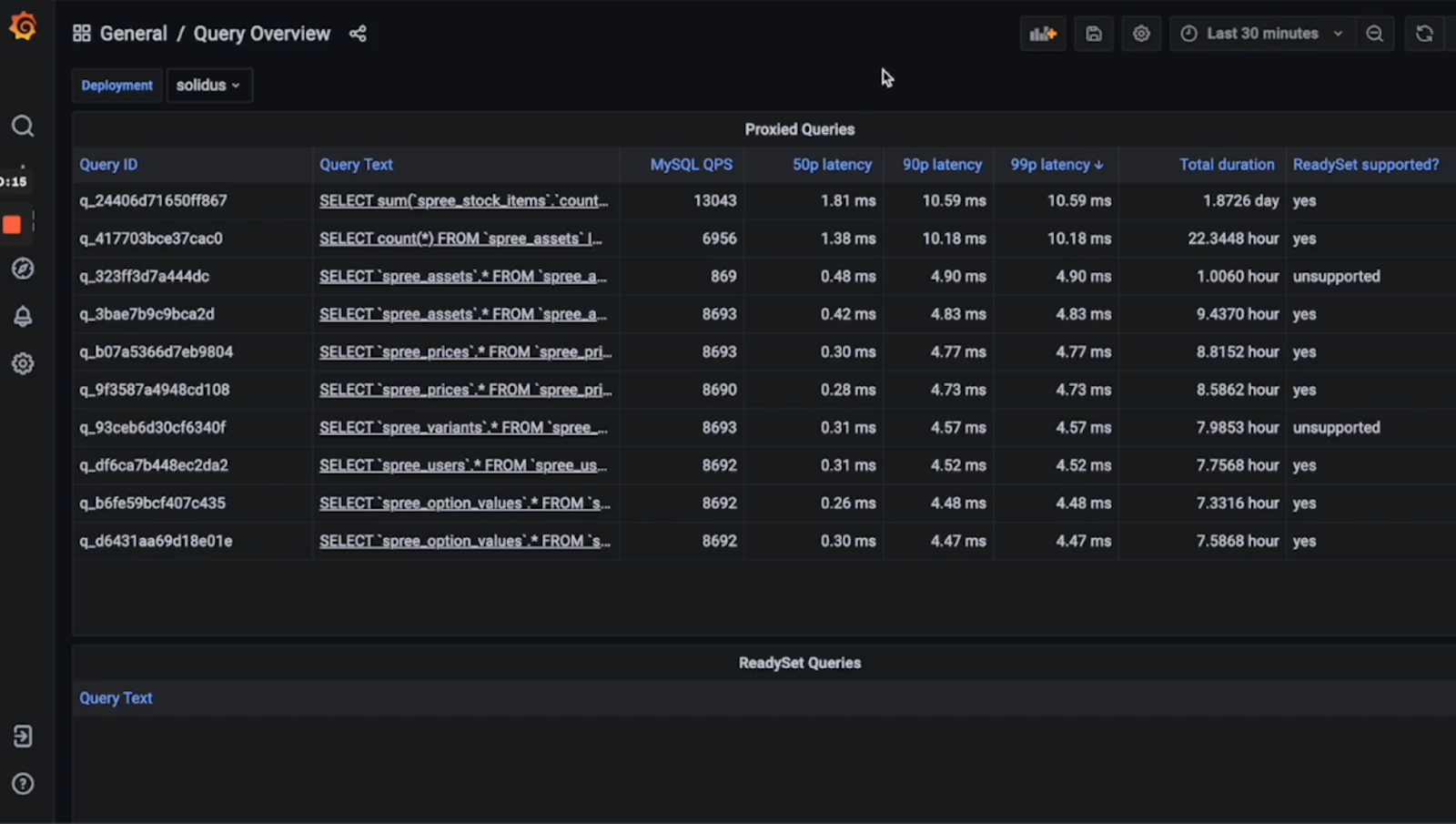
Readyset shows the 50p, 90p, and 99p latencies for query response times. They are key metrics used in performance analysis to understand the distribution of latencies in a system:
- 50p (50th percentile) latency. Also known as the median latency. This means that 50% of your queries or requests are faster than this time, and 50% are slower. It gives a good indication of the typical experience for a user or system interaction.
- 90p (90th percentile) latency. This indicates that 90% of your queries or requests are faster than this time, and 10% are slower. This metric helps in understanding the experience of most of your users, excluding outliers that might be unusually slow.
- 99p (99th percentile) latency. This shows that 99% of your queries or requests are faster than this time, and 1% are slower. It is useful for identifying the long tail of slow requests, which can be critical for understanding and improving users' experience with the worst performance.
You can also graph this data for specific queries:
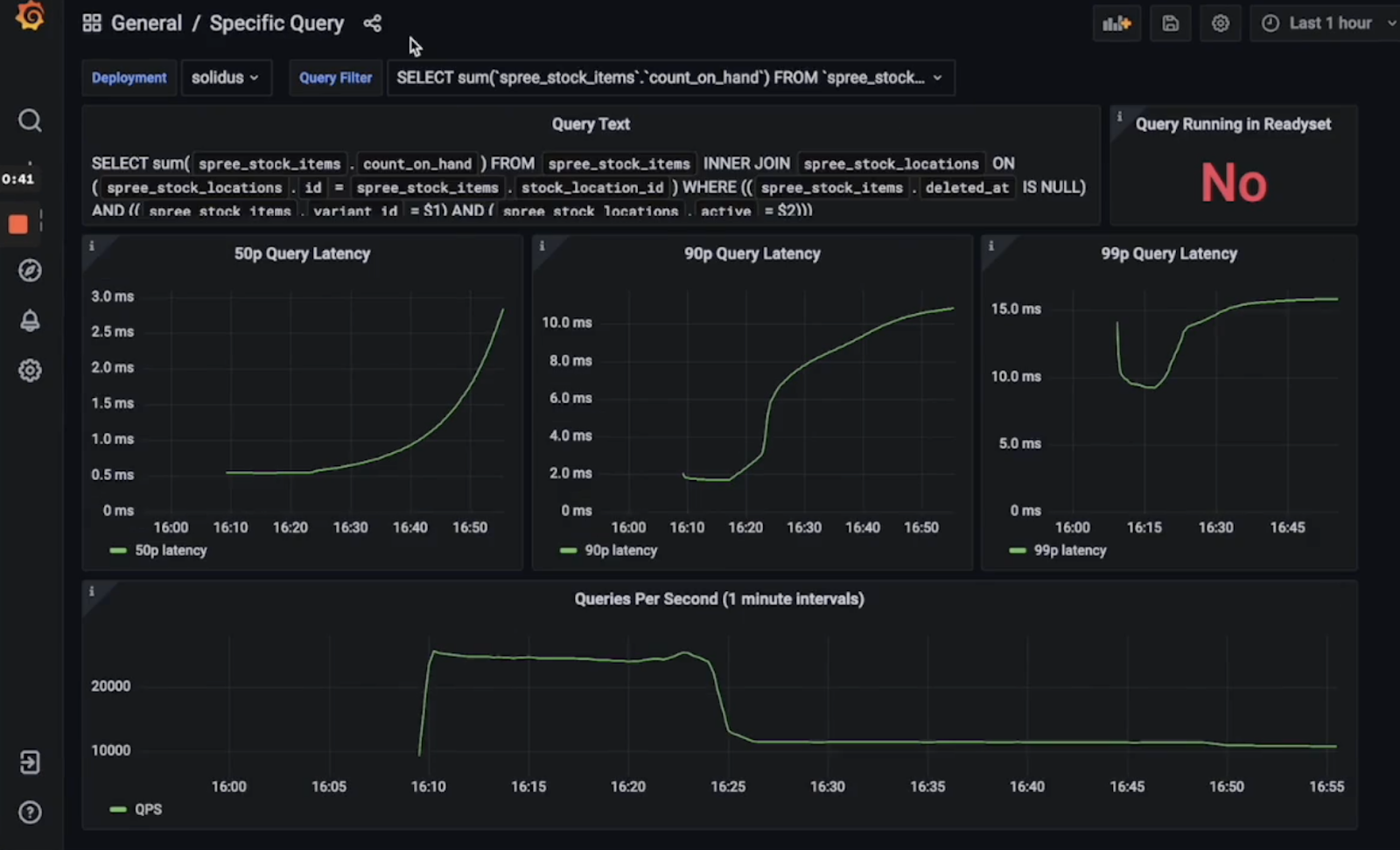
This can tell you which queries are performing poorly and whether this performance changes over time or has any pattern. Here, you can find the longest latency queries and immediately cache them with Readyset.
An Example Caching Workflow With Readyset
Imagine an e-commerce platform with a Postgres database facing performance issues. The platform has experienced high latencies and low throughput, particularly when accessing product information and user profiles.
Step 1: Analyzing Read/Write Ratios
We start by analyzing the read/write ratio to understand the nature of our database workload. First, we enable the pg_stat_statements extension in Postgres to track query statistics:
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;We then query pg_stat_statements to get insights into our read and write operations:
SELECT query, calls, total_time, rows
FROM pg_stat_statements
WHERE query LIKE 'SELECT %' OR query LIKE 'INSERT %' OR query LIKE 'UPDATE %' OR query LIKE 'DELETE %';After analyzing the data, we find a high read/write ratio for product information queries (e.g., 15:1), indicating these are read-heavy and good candidates for caching. Conversely, user profile updates show a lower read/write ratio (e.g., 2:1), suggesting frequent updates.
Step 2: Identifying Temporal Locality and Hotspots
We use database monitoring tools to track access patterns and identify hotspots. In the postgresql.conf, we set:
logging_collector = on
log_directory = 'pg_logs'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_statement = 'all'
Also set:
set log_min_duration_statement=1000;We use pgBadger to analyze the logs. The report shows that queries related to product categories like 'Electronics' are accessed frequently, indicating a hotspot.
Step 3: Query Analysis and Profiling
We use the EXPLAIN command to analyze query plans.
EXPLAIN SELECT * FROM products WHERE category = 'Electronics';The analysis reveals inefficient sequential scans, suggesting the need for better indexing and potential caching.
Step 4: Addressing Query Latencies
We observe the query latencies in the logs:
LOG: duration: 1050 ms statement: SELECT * FROM products WHERE category = 'Electronics';This high latency is a clear indicator of a performance bottleneck.
Step 5: Implementing Caching
Based on our analysis, we decide to cache the frequently accessed product information.
We can do this through Readyset. Readyset requires no changes to our application code. All we have to do is connect Readyset to our Postgres database and then use our Readyset connection string in our application instead of the credentials for the primary Postgres database.
Once this is set up, all the queries from your application to your database will initially be proxied through Readyset. Then you can start caching. In this case, we want to cache our electronics product information. To do so, we just prepend CREATE CACHE FROM to our query:
CREATE CACHE FROM SELECT * FROM products WHERE category = 'Electronics';The results from this query will now be served from Readyset with sub-millisecond latencies. As Readyset monitors the replication stream from the primary database, looking for changes to the data, the cache will be automatically updated whenever the underlying data is updated in the primary database.
Step 6: Monitoring and Continuous Improvement
We continuously monitor query performance using Readyset, which shows us the latencies for each cached query. By analyzing the 50th, 90th, and 99th percentile latencies, we adjust our caching strategies to ensure optimal performance.
By following this approach, we significantly improved the e-commerce platform's performance. The product information queries' latency dropped, and the overall system throughput increased. This real-world example demonstrates the impact of strategic caching in resolving performance bottlenecks in a database-driven application.
Understanding Data Characteristics
The data itself will influence caching strategies. Different data types have unique characteristics that affect how they should be cached. Data size, consistency requirements, and business needs are critical in determining the most effective caching approach. Understanding these characteristics is essential to ensure that the caching strategy aligns with the nature of the data being handled.
Object Size
The size of objects, including individual data items and the results of database queries, is a crucial factor to consider. Object size directly impacts cache storage efficiency, access speed, and overall system performance.
Object Size here could mean:
- Data item size. This refers to the size of individual data items, like rows in a database. Large data items can consume significant cache space, potentially reducing the overall effectiveness of the cache.
- Query result size. The size of data returned by database queries. Some queries might return large datasets, which, when cached, can take up substantial space.
Many databases offer functions to measure the size of rows or tables. In Postgres, you can use pg_column_size to find the size of a column’s value or pg_total_relation_size for the size of a table. E.g.:
SELECT pg_column_size(*) FROM user_data WHERE user_id = 123;Suppose you have a table user_data in a Postgres database, and you frequently query user profiles. Analyzing the size of these profiles helps determine if they should be cached:
SELECT AVG(pg_column_size(*)) FROM user_data;If the average size is relatively small, caching individual profiles might be efficient. However, if the size is large, consider caching subsets of data or using a different strategy, like partial caching.
Be cautious when caching large objects, as they can lead to rapid cache eviction of other items. This can diminish the effectiveness of the cache. If objects are too large to be effectively held in memory, disk-based caching might be more appropriate, though it's slower.
Object size factors into your cache configuration. Consider using eviction policies like Least Recently Used (LRU) for larger objects to maintain cache efficiency.
Consistency Requirements
Consistency here refers to how up-to-date and synchronized the cached data is with the underlying data source. Understanding whether your application needs strict or eventual consistency will guide you in choosing the right caching mechanisms and policies.
Strict Consistency
Strict consistency guarantees that all transactions are executed sequentially, and any read reflects the latest write. It provides the strongest consistency guarantee but can be expensive and impact performance. It is ideal for mission-critical applications where data integrity is paramount. Financial applications, where transaction integrity is crucial, typically require strict consistency. An account balance, for example, must always reflect the most recent transactions.
Two types of caching strategies for strict consistency are:
- Write-through cache. This strategy involves writing data to both the cache and the database simultaneously. It ensures that the cache always has the most up-to-date data.
- Cache invalidation. Another approach is to invalidate the relevant cache entries immediately upon any data modification in the database.
Strict consistency ensures data integrity but can lead to higher latency and increased load on the database due to frequent cache updates or invalidations.
Eventual Consistency
With eventual consistency, writes are eventually propagated to all replicas, but there is no guarantee of how long it takes. Reads may reflect older writes or incomplete data until the replicas are synchronized. Eventual consistency offers high availability and scalability but can lead to inconsistencies for a short period. Social media platforms, where seeing the most up-to-date data is not always critical (e.g., a user's number of followers), can use eventual consistency.
Possible caching strategies for eventual consistency are:
- Time-To-Live (TTL): Cached data is given a TTL, after which it is either refreshed from the database or evicted.
- Lazy Loading: Data is updated in the cache only when requested, leading to potential staleness but reduced load on the database.
Eventual consistency improves read performance, reduces database load, and can serve stale data.
Readyset is eventually consistent, as each new write requires reconstructing the dataflow graph for impacted queries.
The choice between strict and eventual consistency in caching strategies hinges on the application's specific needs. Understanding these requirements is crucial for engineers to design a caching system that balances data integrity with performance and efficiency. By carefully evaluating the nature of the data and its usage patterns, a suitable caching approach can be devised that optimally serves the application's needs.
Business Criticality
Finally, there is a more qualitative characteristic–business criticality. It involves assessing which data is crucial for the functionality and performance of your application and should, therefore, be prioritized in caching strategies. This assessment often requires balancing the need for speed against the tolerance for staleness.
This is mostly about understanding what data is important. Data that significantly impacts the user experience, such as personalized content, frequently accessed user profiles, or dashboard metrics, is often critical for caching. Data that is vital for daily business operations, like transaction records in a financial application or inventory levels in a retail system, should be prioritized for caching.
A few examples of different types of data and their impact on caching are:
- E-Commerce Platforms:
- Product Catalog: Frequently accessed but infrequently updated, making it a good candidate for caching.
- User Shopping Carts: High business criticality but requires strict consistency due to the dynamic nature of the content.
- Content Delivery Networks (CDNs):
- Media Content: Images and videos are crucial for user experience, making them important to cache. They are typically static, allowing for longer TTL values.
- Financial Applications:
- Account Balances: Require real-time accuracy, demanding a strict consistency approach in caching.
- Historical Transaction Data: Less critical for immediate operations, can be cached with eventual consistency.
Within all of these, you are trying to balance speed and staleness. Data that contributes to faster load times and smoother user interactions should be cached, especially if it's accessed frequently. Then, you can think about staleness tolerance by determining how tolerant the business process or user experience is to stale data. For example, slightly outdated product recommendations may be acceptable, but outdated pricing information is not.
This is ultimately a trade-off in terms of speed vs staleness and cost vs benefit. You must analyze the cost of caching (regarding resources and management) against its benefits to business operations and user satisfaction. Plus, you have to factor in developing an effective cache maintenance strategy to maintain data integrity without compromising performance. It requires a deep understanding of the technical aspects of caching and the business or user perspective of data importance.
Caching Done Right
It takes a lot to find the right data to cache. But it is worth it. The effort invested in identifying what to cache, understanding the nature of your data, and aligning your caching strategy with business needs pays off in multiple ways. When done right, caching can significantly improve application performance, enhance user experience, reduce database load, and ultimately contribute to the efficiency and scalability of your systems.
At Readyset, we’re making caching easier. Once you’ve identified the data you need to cache, with Readyset’s help if needed, Readyset will start caching it automatically, giving you sub-millisecond query responses with no extra logic in your application.
Try Readyset Cloud or reach out to us if you have any questions.